Abstract
Inspired by how humans solve a task: only paying attention to the useful part in the vision while neglecting the irrelevant information, we propose an attention mechanism, which learns to focus on the motion part (such as the robot arm and the manipulating target) in an image, while neglecting the noisy background. The model takes RGB images as input, using CNN to extract intermediate spatial features first; then by transporting learned features between two different images and minimizing the reconstruction loss, the attention module is forced to learn a pattern of attention. The output of the model is soft attention map, highlighting the useful part while suppressing background clutter in the image, which can be used as the combined weights for downstream control. Our method is trained in a fully self-supervised way, no manual labeling data is used during training, which increases its ease of use in robot tasks.
The attention training framework:
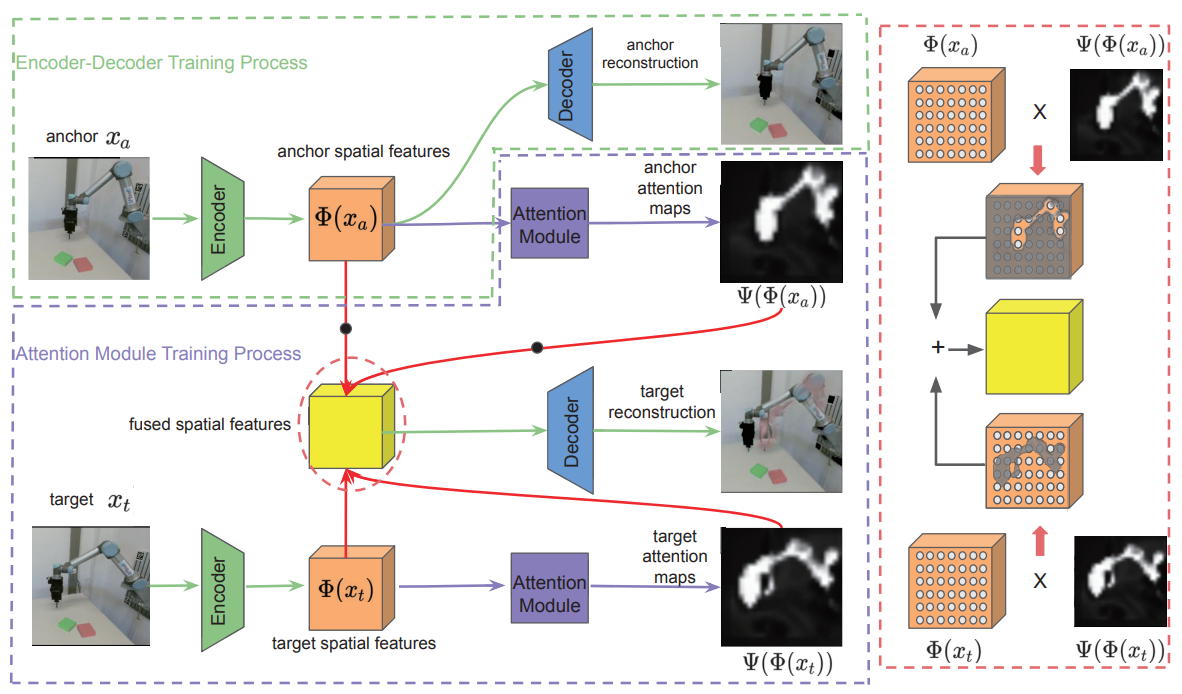
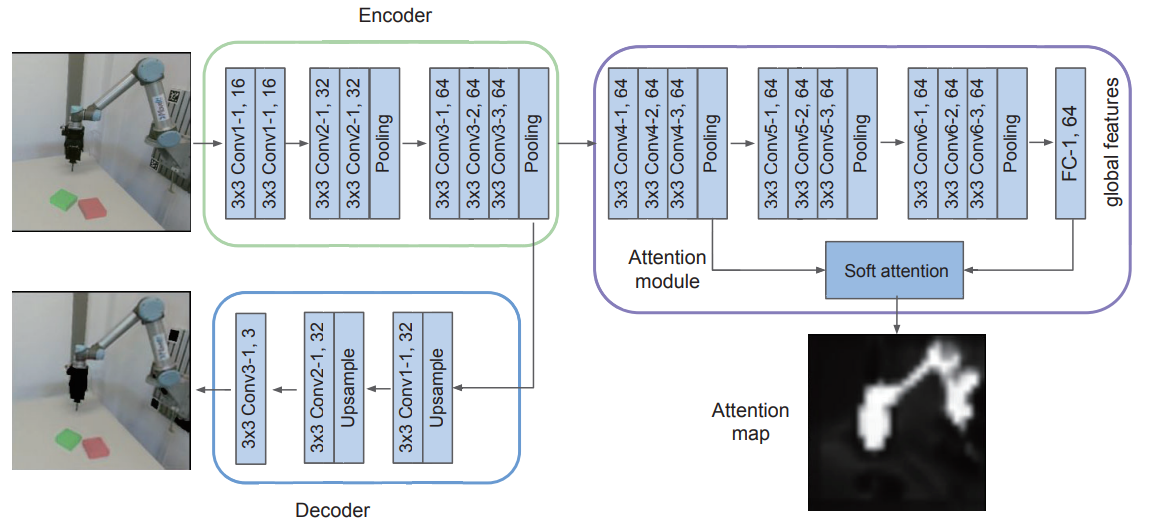
The network structure:
Training results on other reinforcement learning tasks:
